Abstract
Pre-caching images on nova-computes is a tricky issue that may be a big headache to an Openstack Administrator. Here at CERN we have put together a pre-caching system, that has enabled us to send a 1,7 GB image to 1300 servers in under 9 minutes. Keeping in mind the ease of maintenance and scalability at any amount, we wish to present this idea.
Description
Our major concern is the pre-caching of the images on nova-compute nodes. Glance is the central service that provides the infrastructure with VM images. One of the problems that Glance has to encounter, is the scaling of image deploying in large infrastructures. This issue has been addressed by the community with the pre-caching middleware, which stores Glance images on the OpenStack API servers. Here we present an alternative way that it is easy to maintain and deploy, is scalable and, most importantly, is based on existing and proven technologies. Before we present our idea, first we would like to give a brief description of our needs and use case.
The CMS experiment at CERN during the Long Shutdown, decided to “lend” its cluster on the GRID community for their experiments. The HLT (High Level Trigger) cluster is composed by 1300 servers that we want to provide to the GRID site, which include 1 Glance server with 1 Gbps link to the network, 4 servers that host all openstack services on failover with 2 Gbps link each and 1300 hypervisors (with more to come in the future) with 1 Gbps link each.
We have some very specific needs, and thus our utilization of OpenStack may not be the standard case of a cloud provider or any other organization that uses cloud. For instance:
-
each server should run a single virtual machine that consumes all hypervisor’s resources
-
we have a very small variety of images (1-3)
-
we need to start and deploy VMs extremely fast
Despite these specifications, we believe that this presentation may help further develop the caching system in OpenStack.
Building blocks
This pre-caching system is external to OpenStack. This means that zero configurations and patching is needed to the source code, which implies that it can be backported to any version of OpenStack. It contains 2 python scripts, one installed at Glance’s side and the other one on each nova-compute node, an Apache httpd server and multiple squid servers deployed at key points at the infrastructure. In the following image you can see the a tree topology of the pre-caching system that we use in our case. Any kind of topology can be used, that fit the needs of a certain infrastructure.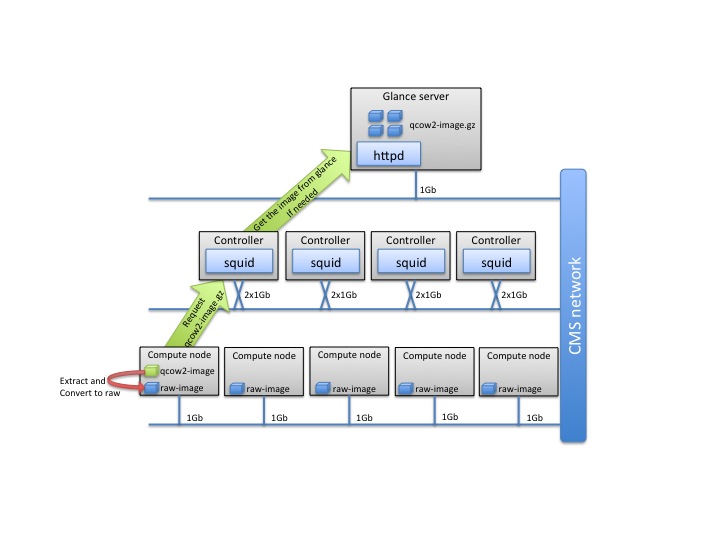
The Glance server hosts the httpd server where we are going to place our image, for pre-caching. The first python script provides a CLI through which one can declare the image-id that they want to pre-cache. The script finds the image, zips it with gzip and places it on the apache httpd folder.
The second step is to ask the nova-computes to fetch the image. At this point one could use the second script (which runs on the nova-compute side), which also provides a CLI which can take the image-id for caching as an input. The script will connect to the httpd server through the squid proxy. It will then retrieve the image and unzip it at the local folders of nova-compute.
Benchmarks
We put this idea to the test and the outcome was a great speedup, as expected. Below we present some numbers on image sizes, network traffic and time.
Image size:
|
Uncompressed
|
gzip -6
|
gzip -9
|
bzip2
|
|
Size
|
1341784064B
1.3GB
|
411246527B
393M
|
408981472B
391M
|
357287908B
341M
|
|
Zip Time
|
—————–
|
1m37s
|
6m58s
|
3m57s
|
|
Unzip Time
|
—————–
|
0m18s
|
0m18s
|
1m5s
|
Network traffic (used gzip -6):
|
No Squid
|
With Squid
|
|
With compression
|
393*8/1024*1300/60
= 66.52(1.1 Hour)
|
393*8/(1024*8)*1300/60
= 8.3 Minutes
|
|
Without compression
|
1300*8/1024*1300/60
= 220.05 Minutes(3.7 Hours)
|
1300*8/(1024*8)*1300/60
= 27.5 Minutes
|
image size * 8 to convert to bits / 1024(Gigabit connection) to get number of seconds to transfer one image * # nodes / 60 seconds / 60 minutes = hours to complete
Glance server: 1 Gbps / Squid server: 2 Gbps / Nova node: 1 Gbps / # Nodes: 1300
Implementation details
In this section we would like to describe further the most important reason that has driven us to develop this system, based on technical details.
1. Why not OpenStack Glance caching
The reason that the OpenStack Glance caching doesn’t fit our needs, is that we demand the lowest possible start time for each VM. This can be done if the images are cached into the nova-compute nodes. Glance caching has no automatic way of pushing the image into the nova-compute nodes.
Glance pre-cache middleware does not support compression. In our case (you can see on the benchmark section the differences in the size), we earned a great benefit in network traffic by compressing the images.
2. Why Squid?
The HLT cluster is already using Squid, so it would be a waste of resources as well as an administrative overhead to install a bunch of additional services on top of the existing ones.
A second argument is that Squid provides a fine set of features that can give great flexibility to administrators regarding how they use the storage amount and policies, the network configuration and topology. Many of the squid features are not available through Glance cache.
There is a small catch using Squid as a medium to serve the images to the nova-compute nodes. When the images are prepared at the Glance side, and copied in the httpd directories, there is no way for them to be pushed to Squid servers. There is a workaround to this problem by sending a signal to a custom script on each Squid server and ask the server to fetch the images, but we thought that this would further complicate the pre-caching system to a great deal.
Instead, we decided to insert a random delay on the nova-compute requests, so that the first connection that will arrive to the squid server will work as a “warm-up” request for the Squid cache.
3. Why Gzip?
The major advantage of Gzip is its low time of decompression. Unlike bzip2, gzip is very fast, even though gzip is 8% less efficient in compressing the same image.
A second advantage of gzip, is its streaming properties (bzip2 can be used too, but as said above, it is slow). When we as a nova-compute to download the image through the Squid network, we uncompress the image at the same time to speed up the process.
4. Monitoring and cleaning?
We created a simple reporting system to help us track down which images are cached where.
Conclusion and future work
As a conclusion to this article we would like to sum up the differences between the current state of both Glance caching and our system, and a future plan.
This is a small table comparing the two frameworks:
|
Glance caching
|
CERN pre-caching System
|
Future Glance pre-caching
|
|
Images are distributed to API servers
|
Images are pushed to the nova-compute nodes
|
Images are pushed to the nova-compute nodes
|
|
No compression
|
Any kind of compression
|
Any kind of compression
|
|
Bind to specific OpenStack version
|
Can work with any OpenStack version
|
Merged with latest version but also can be used as an external system
|
|
API on Glance side
|
external API
|
API on Glance and nova-compute sides
|
Anastasios Andronidis, Olivier Chaze
